
Let’s collaborate — open to all kinds of opportunities.
Let’s collaborate — open to all kinds of opportunities.
Let’s collaborate — open to all kinds of opportunities.

My Role
Product Designer
Platform
Android, iOS, Web
AI Grader: Grading Subjective Answers at Scale with AI
At PhysicsWallah's AI/ML pod, we built AI Grader, a product that evaluates handwritten subjective answers using OCR and LLMs. I was the solo hands-on designer (with regular loops with design leads), driving the product from 0 to live, designing flows that made grading not just faster—but smarter.
At PhysicsWallah's AI/ML pod, we built AI Grader, a product that evaluates handwritten subjective answers using OCR and LLMs. I was the solo hands-on designer (with regular loops with design leads), driving the product from 0 to live, designing flows that made grading not just faster—but smarter.
At PhysicsWallah's AI/ML pod, we built AI Grader, a product that evaluates handwritten subjective answers using OCR and LLMs. I was the solo hands-on designer (with regular loops with design leads), driving the product from 0 to live, designing flows that made grading not just faster—but smarter.
The Impact

100K+ answers graded to date
Student rating: 4.34/5 (internal system) with "ease of use" as one of the top highlights
1000x faster than manual grading (think 2 days vs 30 seconds)
90% cheaper to operate (with projected yearly savings of ₹6 Cr once scaled across paid batches)
Widely used in UPSC and CA categories for practice and daily tests
Highly rated by teachers, especially for daily practice where speed matters
Consistency in grading across students exceeds manual checks in several scenarios
100K+ answers graded to date
Student rating: 4.34/5 (internal system) with "ease of use" as one of the top highlights
1000x faster than manual grading (think 2 days vs 30 seconds)
90% cheaper to operate (with projected yearly savings of ₹6 Cr once scaled across paid batches)
Widely used in UPSC and CA categories for practice and daily tests
Highly rated by teachers, especially for daily practice where speed matters
Consistency in grading across students exceeds manual checks in several scenarios
100K+ answers graded to date
Student rating: 4.34/5 (internal system) with "ease of use" as one of the top highlights
1000x faster than manual grading (think 2 days vs 30 seconds)
90% cheaper to operate (with projected yearly savings of ₹6 Cr once scaled across paid batches)
Widely used in UPSC and CA categories for practice and daily tests
Highly rated by teachers, especially for daily practice where speed matters
Consistency in grading across students exceeds manual checks in several scenarios
Problem Statement
Manual grading is dependable—but slow, inconsistent, and expensive at scale:
For Students:
Feedback was delayed (waiting days for corrections)
Lack of consistency in scoring and subjective bias
Limited annotation-based feedback—they got marks, but not learning
For Teachers & Admins:
Manual grading is not scalable for daily practice sets
Teachers are overburdened, and human error causes uneven evaluation
Business & Tech Constraints:
The rise of LLMs meant now or never—we had to move fast
Annotation-based AI feedback (on actual copy) wasn’t possible yet, so a fallback UI had to be designed using score parameters placed alongside student answers
Manual grading is dependable—but slow, inconsistent, and expensive at scale:
For Students:
Feedback was delayed (waiting days for corrections)
Lack of consistency in scoring and subjective bias
Limited annotation-based feedback—they got marks, but not learning
For Teachers & Admins:
Manual grading is not scalable for daily practice sets
Teachers are overburdened, and human error causes uneven evaluation
Business & Tech Constraints:
The rise of LLMs meant now or never—we had to move fast
Annotation-based AI feedback (on actual copy) wasn’t possible yet, so a fallback UI had to be designed using score parameters placed alongside student answers
Manual grading is dependable—but slow, inconsistent, and expensive at scale:
For Students:
Feedback was delayed (waiting days for corrections)
Lack of consistency in scoring and subjective bias
Limited annotation-based feedback—they got marks, but not learning
For Teachers & Admins:
Manual grading is not scalable for daily practice sets
Teachers are overburdened, and human error causes uneven evaluation
Business & Tech Constraints:
The rise of LLMs meant now or never—we had to move fast
Annotation-based AI feedback (on actual copy) wasn’t possible yet, so a fallback UI had to be designed using score parameters placed alongside student answers

Our Solution
We focused on making AI feedback clear, usable, and believable, without trying to mimic manual grading superficially.
Key Features Designed:
Support for both single-question in initial phases
Answer upload flow with clear scanning, submission, and progress states
Fallback wait handling for LLM processing >10s—engaging and non-disruptive
Parameter-based feedback view with score breakdowns. Students were familiar with Parameter already.
Model answer comparison view to give students context and validate AI responses
Building Trust with AI Feedback:
We knew trust can’t be demanded, so we let users compare their answers with model ones
Used score parameters that students already knew to ensure feedback felt relevant
UX Considerations:
Result Summary Page: Packed with data, needed clean IA to make it digestible
Answer Upload as multiple images: Designed for tech-light users (our TG wasn’t app-savvy)
Design Process:
Flow was simple and pretty much predefined—we spent more time iterating on IA and visuals
Constant brainstorming with PMs; tech feasibility checks with ML team
Built using PW’s existing design system (module inside the main app)
One That Got Away:
Annotated feedback on actual user copy: designed, but on hold due to tech constraints. (We still show this in the case study as a concept demo.)
We focused on making AI feedback clear, usable, and believable, without trying to mimic manual grading superficially.
Key Features Designed:
Support for both single-question in initial phases
Answer upload flow with clear scanning, submission, and progress states
Fallback wait handling for LLM processing >10s—engaging and non-disruptive
Parameter-based feedback view with score breakdowns. Students were familiar with Parameter already.
Model answer comparison view to give students context and validate AI responses
Building Trust with AI Feedback:
We knew trust can’t be demanded, so we let users compare their answers with model ones
Used score parameters that students already knew to ensure feedback felt relevant
UX Considerations:
Result Summary Page: Packed with data, needed clean IA to make it digestible
Answer Upload as multiple images: Designed for tech-light users (our TG wasn’t app-savvy)
Design Process:
Flow was simple and pretty much predefined—we spent more time iterating on IA and visuals
Constant brainstorming with PMs; tech feasibility checks with ML team
Built using PW’s existing design system (module inside the main app)
One That Got Away:
Annotated feedback on actual user copy: designed, but on hold due to tech constraints. (We still show this in the case study as a concept demo.)
We focused on making AI feedback clear, usable, and believable, without trying to mimic manual grading superficially.
Key Features Designed:
Support for both single-question in initial phases
Answer upload flow with clear scanning, submission, and progress states
Fallback wait handling for LLM processing >10s—engaging and non-disruptive
Parameter-based feedback view with score breakdowns. Students were familiar with Parameter already.
Model answer comparison view to give students context and validate AI responses
Building Trust with AI Feedback:
We knew trust can’t be demanded, so we let users compare their answers with model ones
Used score parameters that students already knew to ensure feedback felt relevant
UX Considerations:
Result Summary Page: Packed with data, needed clean IA to make it digestible
Answer Upload as multiple images: Designed for tech-light users (our TG wasn’t app-savvy)
Design Process:
Flow was simple and pretty much predefined—we spent more time iterating on IA and visuals
Constant brainstorming with PMs; tech feasibility checks with ML team
Built using PW’s existing design system (module inside the main app)
One That Got Away:
Annotated feedback on actual user copy: designed, but on hold due to tech constraints. (We still show this in the case study as a concept demo.)

Designed for both App and Web
Designed for both Mobile and Web. And mobile, like all other PW modules, comes in both light and dark mode.
Designed for both App and Web
Designed for both Mobile and Web. And mobile, like all other PW modules, comes in both light and dark mode.
Designed for both App and Web
Designed for both Mobile and Web. And mobile, like all other PW modules, comes in both light and dark mode.
End to End Flow
End to End flow of student submitting an answer and getting their Feedback.
End to End Flow
End to End flow of student submitting an answer and getting their Feedback.
End to End Flow
End to End flow of student submitting an answer and getting their Feedback.
Incase it takes long...
Fallback case to keep wait time smooth and stress-free (Comes when processing takes > 10 secs)
Incase it takes long...
Fallback case to keep wait time smooth and stress-free (Comes when processing takes > 10 secs)
Incase it takes long...
Fallback case to keep wait time smooth and stress-free (Comes when processing takes > 10 secs)
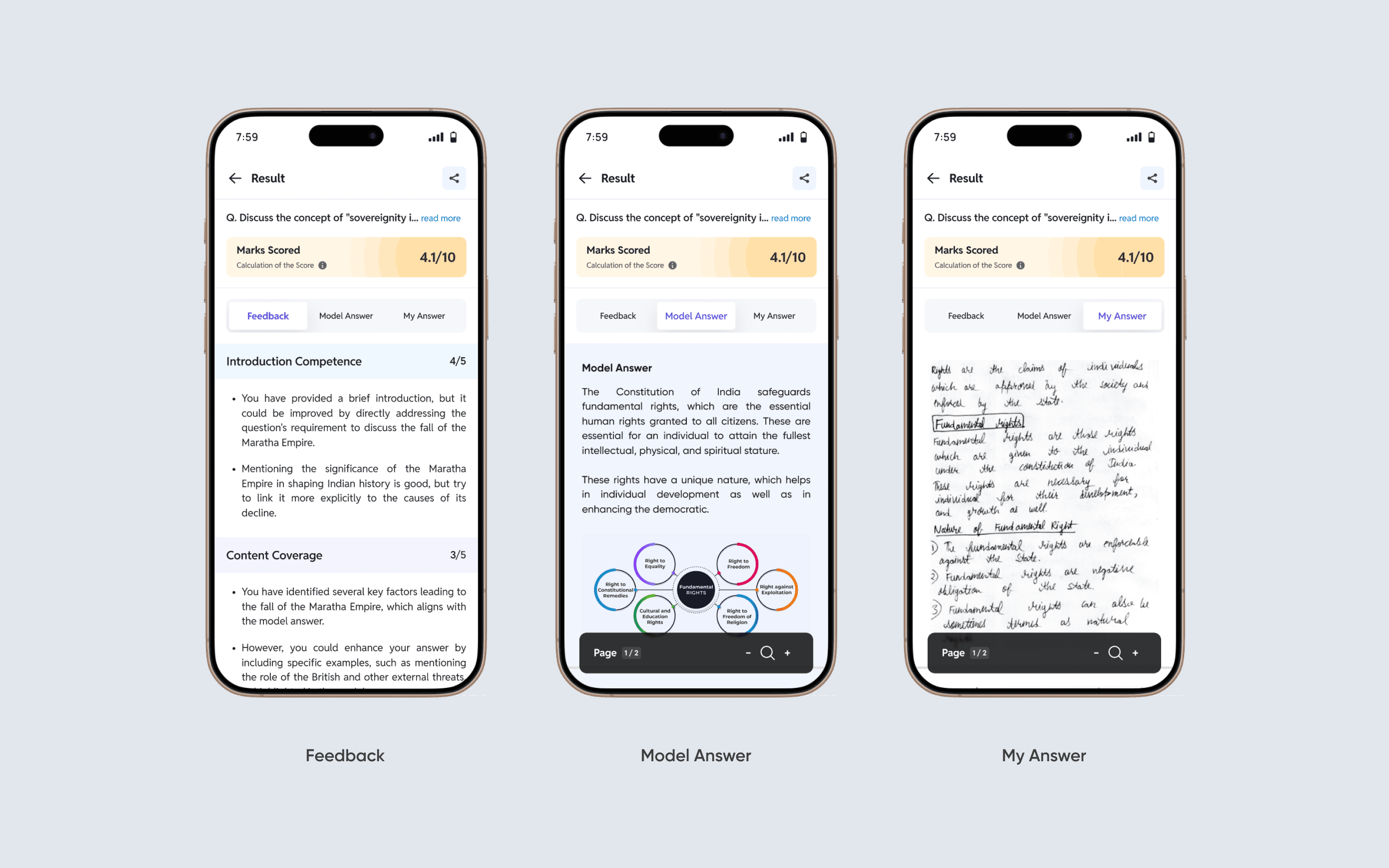
Side by Side for comparison
Score breakdowns on familiar parameters—clear, clean, and personalized. Easily comparable with Model Answer & Submitted copy.
Side by Side for comparison
Score breakdowns on familiar parameters—clear, clean, and personalized. Easily comparable with Model Answer & Submitted copy.
Side by Side for comparison
Score breakdowns on familiar parameters—clear, clean, and personalized. Easily comparable with Model Answer & Submitted copy.
The actual way feedback should've been!
Feedback designed to mimic real teacher feedback on user copy—launching soon as model matures.
The actual way feedback should've been!
Feedback designed to mimic real teacher feedback on user copy—launching soon as model matures.
The actual way feedback should've been!
Feedback designed to mimic real teacher feedback on user copy—launching soon as model matures.
Upload images feels like a breeze
The Image uploading flow for answer is completely intuitive and easy to use
Upload images feels like a breeze
The Image uploading flow for answer is completely intuitive and easy to use
Upload images feels like a breeze
The Image uploading flow for answer is completely intuitive and easy to use
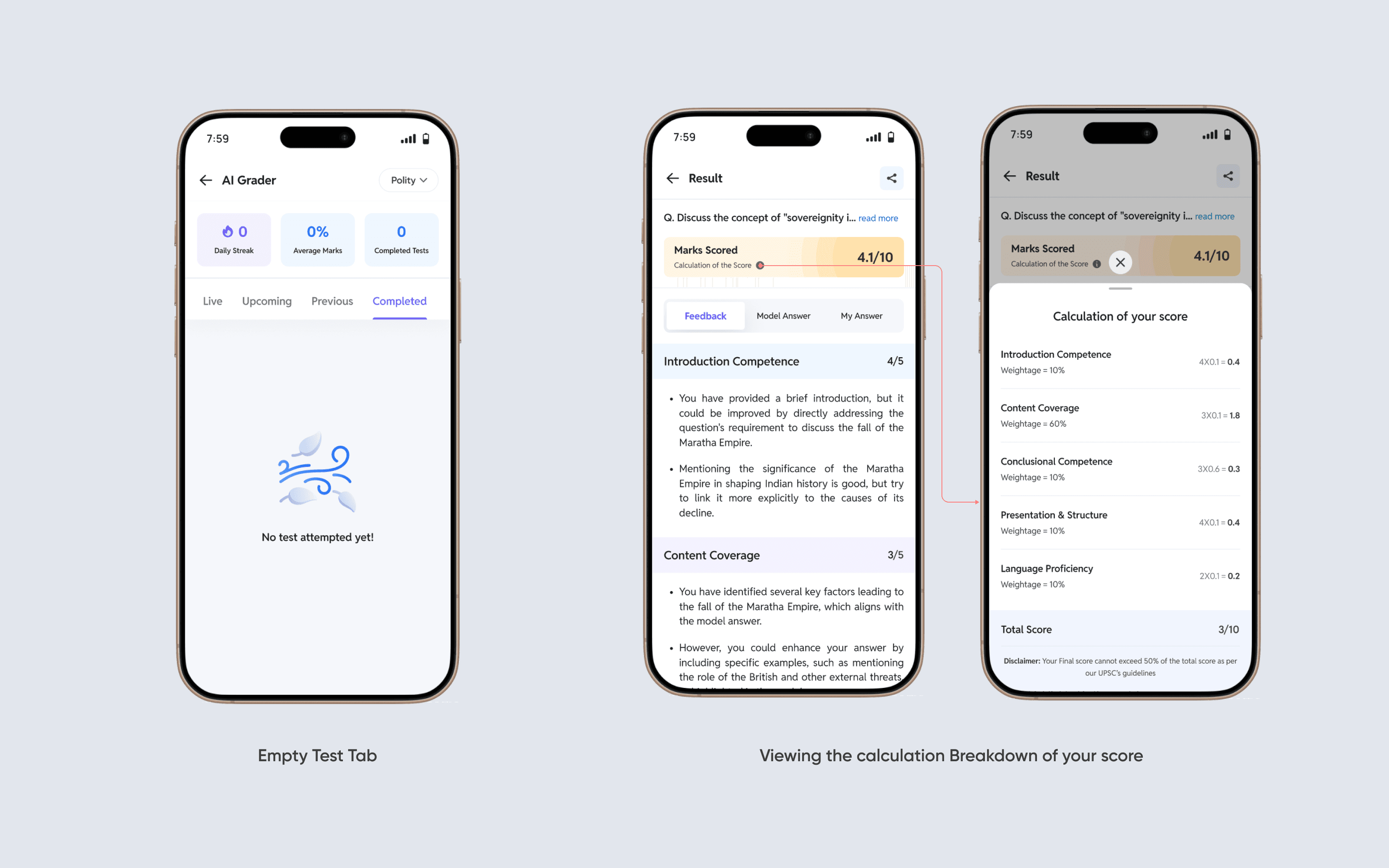
Miscellaneous
Just some other screens and states that made the flow complete
Miscellaneous
Just some other screens and states that made the flow complete
Miscellaneous
Just some other screens and states that made the flow complete
Reflection & Learnings
One big lesson? Cross-team collaboration matters. Our Streak feature clashed with another team’s parallel effort, and that could’ve been avoided with more sync. That effort could have been saved by better collaboration
Also, design processes are flexible. The clean “ideal” loop doesn’t always apply. You do what gets the job done fastest without compromising quality.
Post-launch, we added support for multi-question tests and Multi Language Support (English & Hindi) as our model matured and showed strong performance. More iterations are in the pipeline.
Thanks for reading :) If you're interested in knowing more about this, DM me!
One big lesson? Cross-team collaboration matters. Our Streak feature clashed with another team’s parallel effort, and that could’ve been avoided with more sync. That effort could have been saved by better collaboration
Also, design processes are flexible. The clean “ideal” loop doesn’t always apply. You do what gets the job done fastest without compromising quality.
Post-launch, we added support for multi-question tests and Multi Language Support (English & Hindi) as our model matured and showed strong performance. More iterations are in the pipeline.
Thanks for reading :) If you're interested in knowing more about this, DM me!
One big lesson? Cross-team collaboration matters. Our Streak feature clashed with another team’s parallel effort, and that could’ve been avoided with more sync. That effort could have been saved by better collaboration
Also, design processes are flexible. The clean “ideal” loop doesn’t always apply. You do what gets the job done fastest without compromising quality.
Post-launch, we added support for multi-question tests and Multi Language Support (English & Hindi) as our model matured and showed strong performance. More iterations are in the pipeline.
Thanks for reading :) If you're interested in knowing more about this, DM me!